Basically, PolyBase allow you to connect
- structured and
- un-structured data
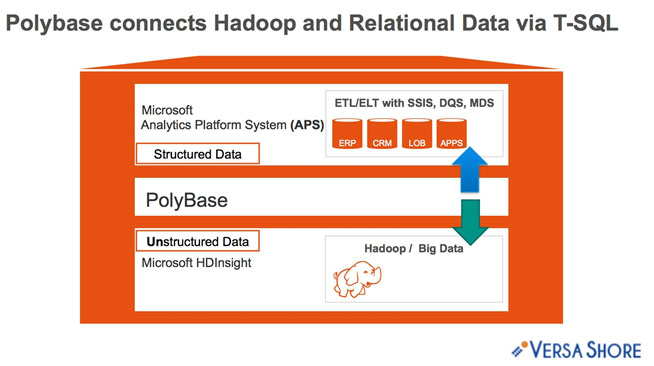
in a Microsoft Analytics Platform System (APS) appliance using T-SQL.
Project PolyBase was based on the research done by Technical Fellow David DeWitt at Gray System Lab. The primary goal was to find an easy, seamless way to integrated unstructured Big Data with relational, structured data residing in an RDBMS. PolyBase make it easy to blend all data types using the familiar syntax of T-SQL. Here is a simple example on how to create an external table with data sourced from a Hadoop cluster.
–Create a new external table in APS
CREATE EXTERNAL TABLE [ database_name . [ dbo ] . | dbo. ] table_name
( <column_definition> [ ,…n ] )
WITH ( LOCATION = ‘hdfs_folder_or_filepath’,
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,…n ] ]
) [;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value
}
The Hadoop region is not automatically installed on APS. It is an option and therefore needs to be configured appropriately in APS V2 AU1 and beyond.
Here is a list of pre-requisites before Hadoop can be used on APS:
- Java runtime libraries need to be installed
- Static PDW_User has to be created on Hadoop
- Hadoop connectivity has to be enabled and configured for
- HDInsight,
- Hortonworks or
- Cloudera
This is huge for SQL Server customers looking to integrate Big Data with their Relational Data. By choosing APS/PolyBase, they can extend their existing in-house staff that is already familiar with T-SQL. Additionally the fully parallelized nature of PolyBase allows users to write heavy duty, industrial strength queries that can handle Petabytes of data without breaking down.
Stay tuned for more blogs on Microsoft APS.
